CLICK HERE: Notebook Version
CLICK HERE: Medium Blog
Overview
In this project, I present a Naive-Bayes-Logistic-Regression model to classify the sentence data on Quora.com as sincere or insincere questions, with the performance (f1 and AUC score) comparing to the complex RNN model. To feed into that machine learning model, the text data are transformed into Document-Term Matrix (Bag of Words). Besides, other topics like TF-IDF matrix, Lemmatization are also discussed.
Challengs
The main challenge is to build a machine learning model with far less training time than RNN but at the same time with the performance as good as a comlex RNN;
Solutions
Transformed the input data of Logistic regression model into theoretical prior probability by Naive Bayes function and then using L2 regularization to penalize those weights different from the theoretical inferencing.
Details
Since I’ve already written an article about it on Medium.com, please check it out through the link above. I will display some basic data explorations here:
The data looks like this: The first column is for unique identifier, which is useless into this problem. The second columns is the sentence and the third column is the binary target (0 as sincere question, 1 as insincere question) 
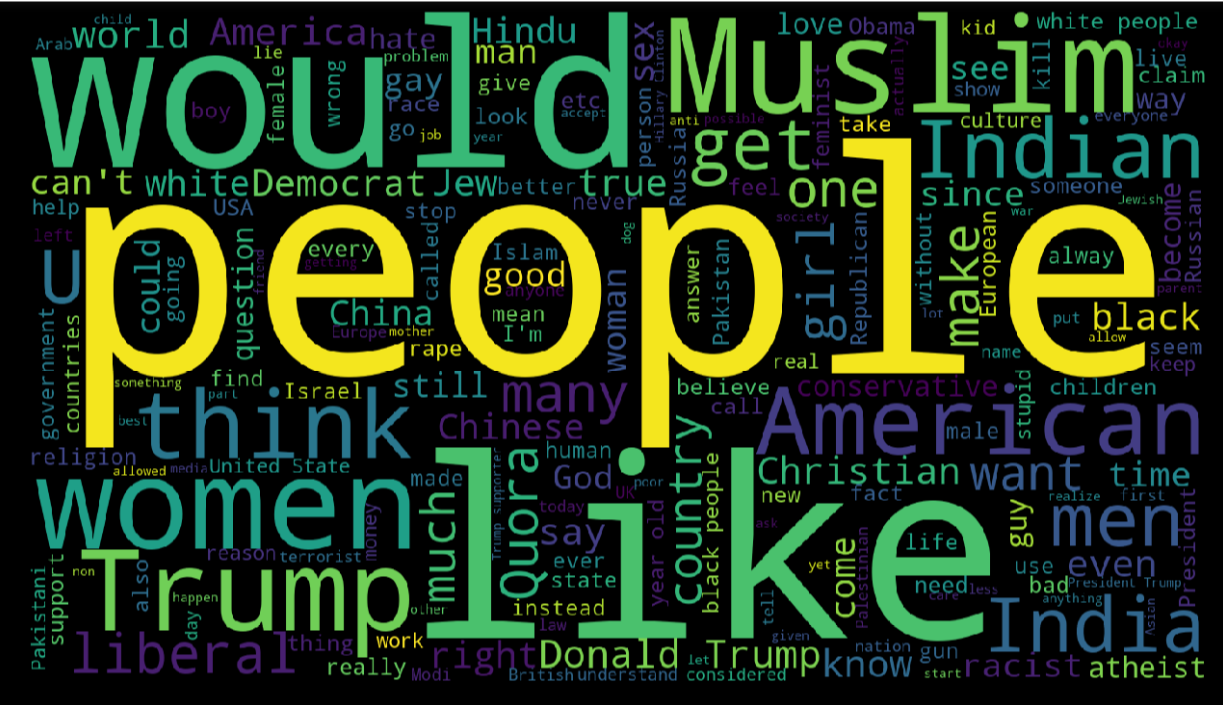
The dataset is unbalanced, so for the metrics used to evaluate the model, instead of accuracy, the F1-score and AUC will be more proper to use. I also draw some wordclouds to look at which word or which pairs of word appear more often in Sincere or Insincere questions. 

The Document-Term Matrix mentioned before looks like this image: 
please check it out through the link above.